For about 75 blocks yesterday I had a fully sync'd MySQL DB of the blockchain - as of block 439,395 BC (before corruption). Here are some numbers at that time:
124 GB Full Disk Size, consisting of:
3.1 GB Bitcoin blockchain (pruned, mostly 2.7GB of chainstate)
57 GB MySQL DB of which,
30 GB is MYD data files
27 GB is MYI index files (can be rebuilt from data)
And then there is the "witness" data (signatures)
64 GB blobs.dat (in the sqlchain directory)
The 27GB of index files needs to be on fast SSD storage during a full sync. The blockchain and data files can get by fairly well on spinning platters. And the blobs data could be offline if need be. There is a fancy trick I figured out for offline witness data, but more on that later. Going forward now I'll be testing with all data on a 300GB RAID-10 hard disk to see how well it performs for the demo API server.
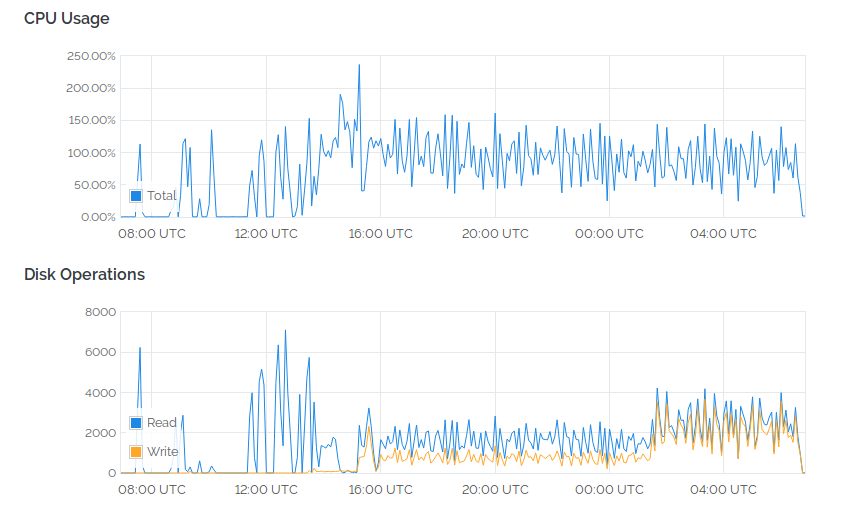
The time to sync was really hard to pin down because I had several changes in operating conditions over the sync period, and my record keeping was utterly un-scientific. My recollection is taking about 5 days to reach block 350,314 on the 4vCPU-4GB-300GB VPS resulting in the layout below before I then rsync'd over to the (semi) dedicated server.
@sql 350314 / btc 351040
pruned 250 of 252 files
dux /var/data
19G /var/data/mysql
776K /var/data/www
1.3G /var/data/bitcoin
21G /var/data/sqlchain
41G /var/data
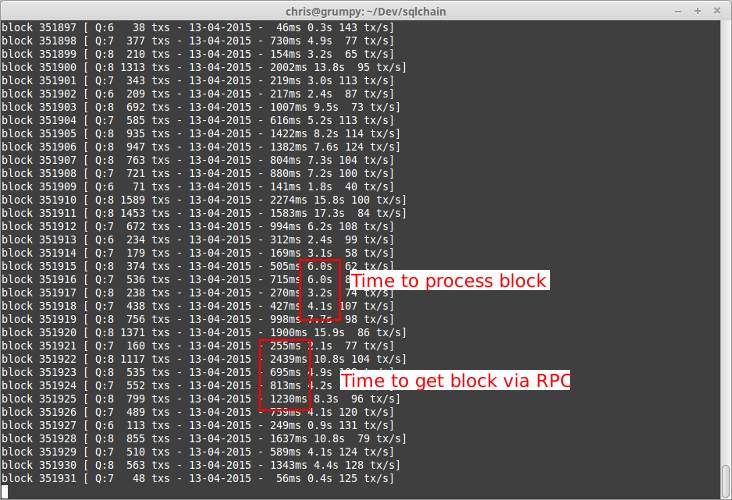
During most of that time I had bitcoind blocked with iptables rules (blkbtc utility) so it would respond to RPC calls without being able to add new blocks. It downloads and verifies much faster than sqlchaind can add them to the MySQL DB. Yes, bitcoind gets so gung-ho on verifying blocks that there is little CPU time left for much else, and if sqlchaind cannot process blocks then they don't get pruned - which was a main focus of my test case here.
After the rsync to the faster SSD based system, processing blocks sped up by a factor of 5-8 times. I altered the code to use two threads with queueing for inserting SQL data; which helped make better use of the multiple cores. From my billing record this system ran for 102 hours but some of that time was a rebuild due to a screw up I made during the testing of multi-thread code. I lost around 24 hours on that, leaving 78 hours to actually finish the sync. All told, about 8 days for a full sync, though if started on a faster system I'd bet on more like 4-5 days.
In comparison it seems a regular sync of bitcoind can take as little as 8 hours and currently uses either 108 GB of disk space or, with txindex turn on, around 226 GB. So overall I'm pretty happy with this. I get a lot of query functionality for about half the size of the txindex blockchain. And witness data purging is still an option for reducing space. Removing blobs.dat cuts out 64 GB giving a nice lean 60 GB queryable database.
And talking about blobs, here is the trick I worked out. If, for example, you are on a VPS with < 100 GB SSD available and don't want to splurge on double that (seems these choices go up double each price step) then it's possible to have your cake and eat it. You want to keep that disk space for MySQL data but not entirely throw out the witness data because maybe later you will use it. As you near full capacity during the sync you can briefly stop sqlchaind, and rename blobs.dat (eg. blobs.0.dat) and copy that offline. Now use the truncate command to create a sparse zero byte file of exactly the same size, eg.
truncate -s 34765456543 blobs.dat
This file takes up zero disk space but holds the positional state for new sig data appended. It's a "hollow" blob. As more data is added you can repeat the process again but to avoid copying that many zeros bytes across the net I'd suggest first copying only the new data off the top (to, eg. blobs.1.dat with dd) and again making a new truncate file for the new total size.
dd if=blobs.dat iflag=skip_bytes skip=34765456543 bs=1M of=blobs.1.dat
Essentially you can log witness data to cheap storage as you go using very little of the limited VPS space. Now, if I had a 512 GB SSD sitting in a dedicated colo server I wouldn't bother with all this rubbish but then I wouldn't be pushed to figuring out these nifty workarounds.
The Vultr server cost me $5 to run the tests. I deposited $5 via Paypal (they do take bitcoin but I haven't needed to fund it more yet), and they gave me a $20 bonus trial deposit. After spinning up 6 different servers and mounting 3 various (100,50,25 GB) block storage volumes I've used a total of $12. Slow hand clap.
As I write this I am nearing completion of the blockchain for a second time and will finally be restarting sqlchaind and moving back to the smaller VPS to launch the demo API server.