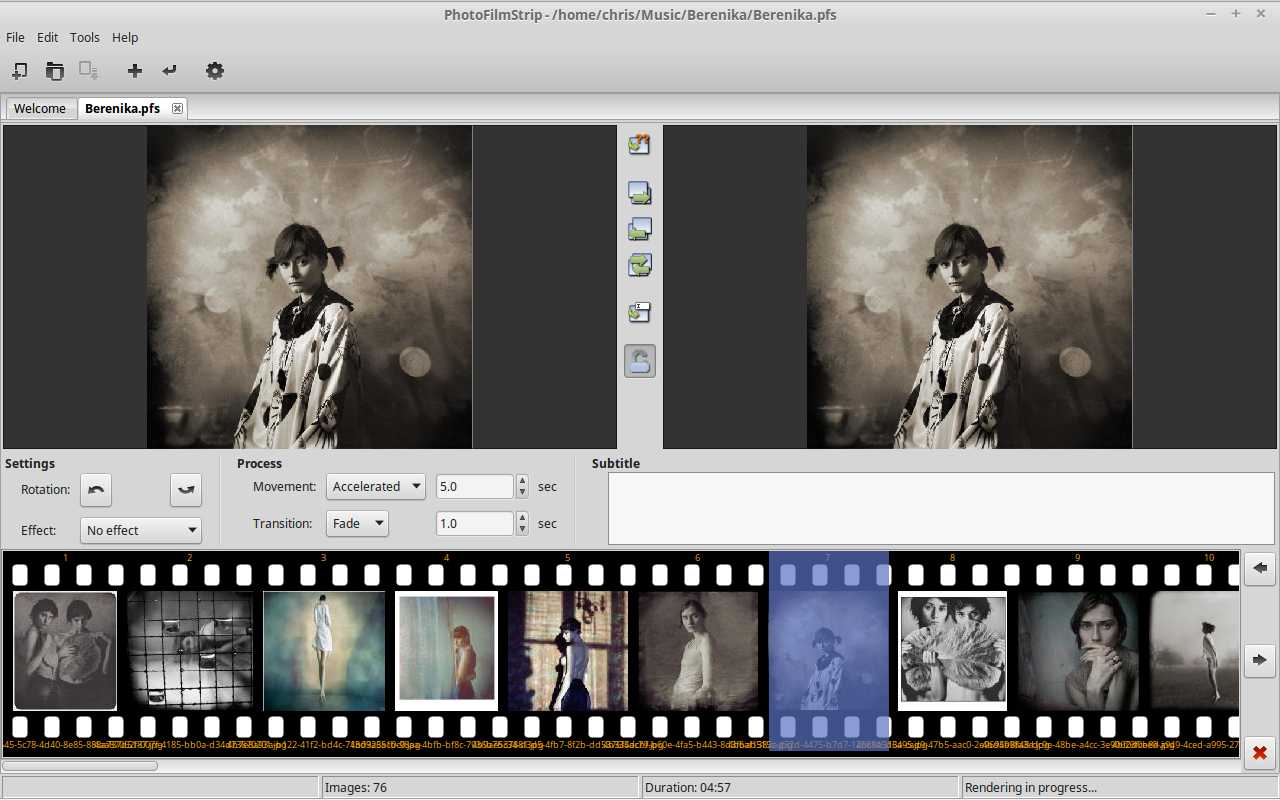
 Today I found myself wanting to produce a quick slideshow video combining some photos and some music. A pretty awesome tool for this is PhotoFilmStrip. I tried a few others but this was the the easiest I found that also produced excellent output quality. It did have a couple limitations which I resolved with a very modest bit of hacking that I'm going to share here.
Today I found myself wanting to produce a quick slideshow video combining some photos and some music. A pretty awesome tool for this is PhotoFilmStrip. I tried a few others but this was the the easiest I found that also produced excellent output quality. It did have a couple limitations which I resolved with a very modest bit of hacking that I'm going to share here.
Adding H264 Support
The first thing I wanted was output in h264 MP4 format for viewing in XBMC. After digging through a bit of python code I found that a few small mods would achieve this. I've posted these changes as a Gist so others can use them. Note that you should back up the two relevant files in case of problems, and also need to edit them as root.
I just add a new class similar to the MPEG4-XVID one that has workable Mencoder options, and then make it available in the list shown by the render dialog. This worked quite well for me and I tested the output files in XBMC (after a bit of tooling around with test values). There is some warnings in the err log file but these did not seem to cause any problems.
Disabling Ken Burns
The next thing I found a bit limiting was not being able to bypass the pan/zoom "Ken Burns" effect easily. You can manually stop it by clicking the lock icon (between start/end images), and then adjusting the image scaling (with scroll wheel/mouse movements) but it's not accurate and must be done for every image in the slideshow. So I went looking for a way to edit the slideshow control settings and found it's just a sqlite3 database file. That's cool. So with a bit more fiddling I found I could write a one line sql statement that would instantly set all images to center stage and have no pan/zoom - like a simpler slideshow program might do. The nice thing about this method is you could potentially get very fancy by generating the slideshow control pan/zooms with a small script. I don't need that now but it's nice to know it could be done quite easily.
So here's the very simple sql for centering in fixed position (in HD resolution 1280x720, change accordingly if desired):
update picture set start_left=-(1280-width)/2,start_top=-(720-height)/2,start_width=1280,start_height=720, target_left=-(1280-width)/2,target_top=-(720-height)/2,target_width=1280,target_height=720;
You can put this in a file and pipe it into sqlite3 on the command line or use echo, like this:
echo "update picture set start_left=-(1280-width)/2,start_top=-(720-height)/2,start_width=1280,start_height=720, target_left=-(1280-width)/2,target_top=-(720-height)/2,target_width=1280,target_height=720;" | sqlite3 path/to/slideshow.pfs
If you want to avoid the command line then any sqlite3 editor can be used. I initially tested this with the SQLite Manager Firefox plugin by selecting the pfs file and then executing the sql statement from there.
As a side note, something that's not immediately clear with PhotoFilmStrip is when you add an audio file to the project it forces the slideshow length to match the audio and then adjusts the timing of each image (proportionately according to actual time setting on each) so the sum of all image times match the audio. This is handy as long as that's what you want.
It would be nice to be able to set a background image for the slideshow. I haven't looked into this yet. Maybe I will some day.

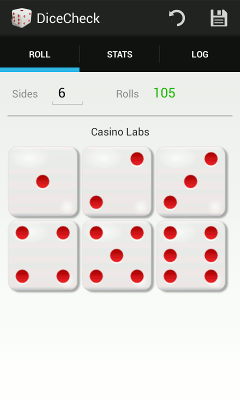 Last summer I wrote an Android app. It was my first Java in more than a decade and mostly my intent was to figure out what this platform was all about. I needed something fairly easy but it still had to touch on many aspects of the user interface and use enough API calls to be a good learning vehicle. A dice bias/fairness testing app seemed a good fit.
Last summer I wrote an Android app. It was my first Java in more than a decade and mostly my intent was to figure out what this platform was all about. I needed something fairly easy but it still had to touch on many aspects of the user interface and use enough API calls to be a good learning vehicle. A dice bias/fairness testing app seemed a good fit. 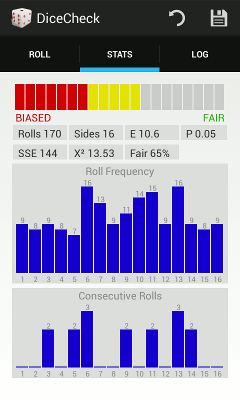 It seemed like an app could save the manual work, and also allow for keeping a dice log so that you could keep doing an ongoing evaluation (while using the dice in a game of some sort). This is what apps are good for - removing the grunt work.
It seemed like an app could save the manual work, and also allow for keeping a dice log so that you could keep doing an ongoing evaluation (while using the dice in a game of some sort). This is what apps are good for - removing the grunt work.